

Intermediate workshop
AI-Assisted Development Foundations
Master the principles behind AI code generation and build a context ecosystem that works with any AI coding assistant.
Learn more
There is an old joke that there are only two hard things in computer science: cache invalidation and naming things. I propose a third. Watching an AI agent confidently rewrite your authentication layer based on a sarcastic PR comment from 2021.
When we deployed agents for actual engineering work, model intelligence was never the bottleneck. The models read and generated code just fine. The real problem was something anyone in a massive engineering org already knows. Tribal knowledge is scattered everywhere.
The current truth doesn't live in one clean document. It is spread across ADRs, RFCs, meeting notes, transcripts, steering files, and that one highly opinionated debate by the coffee machine.
Point an AI agent at your repository's raw documents and it won't inherently know which ADR was accepted, which RFC is provisional, or which decision was silently overturned over beers three years ago. The agent can search files incredibly fast. It lacks project memory and architectural judgment.
Normally, this is where I would drag design systems into the chat. They are the perfect victim of scattered knowledge, full of silent rules about why a button can't be exactly 42 pixels wide. But for your sake (and my own sanity), I am going to exercise rare restraint and demonstrate this using an architectural layer that is just as fragile when an AI guesses wrong: Server-Side Rendering.
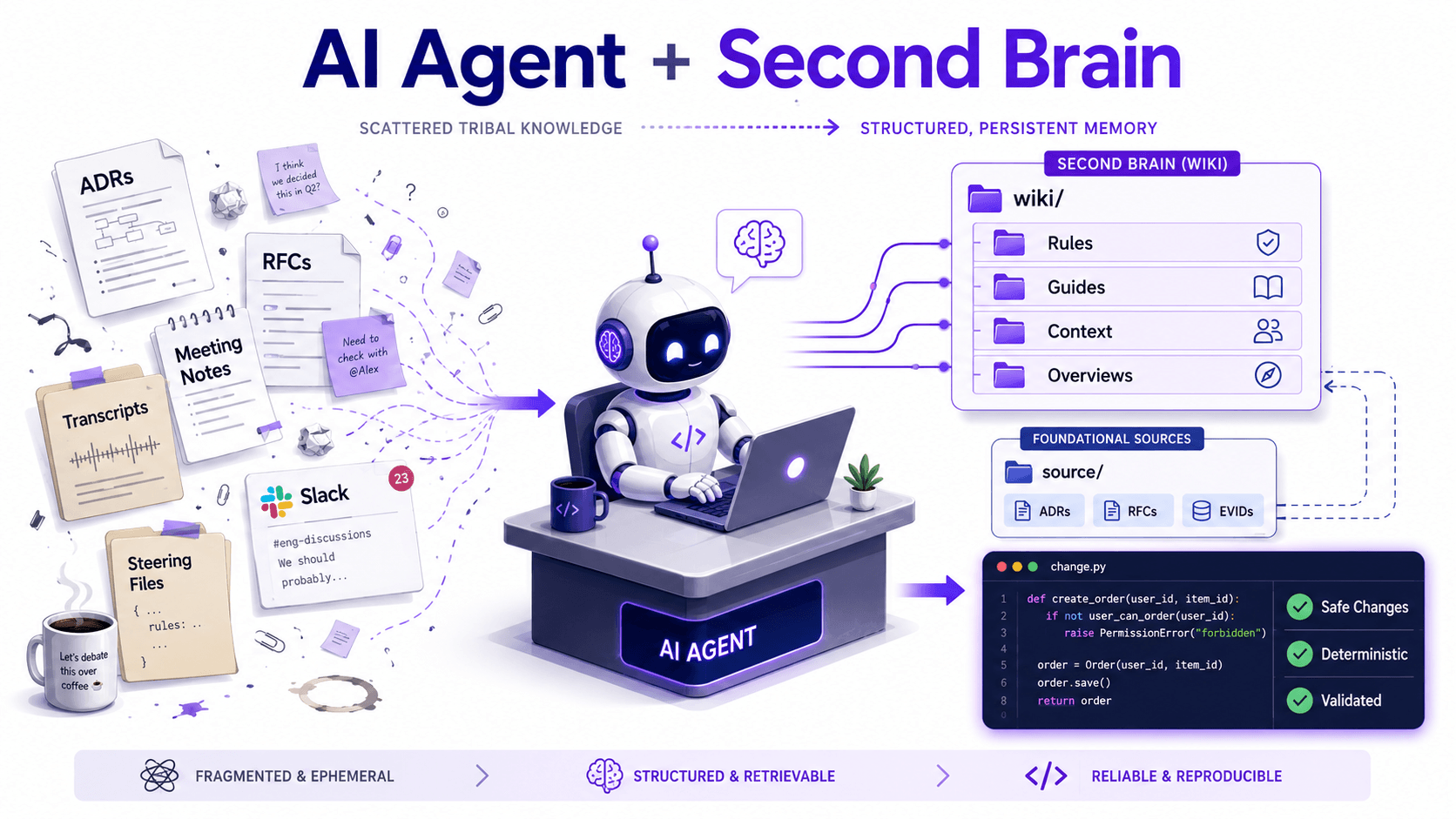
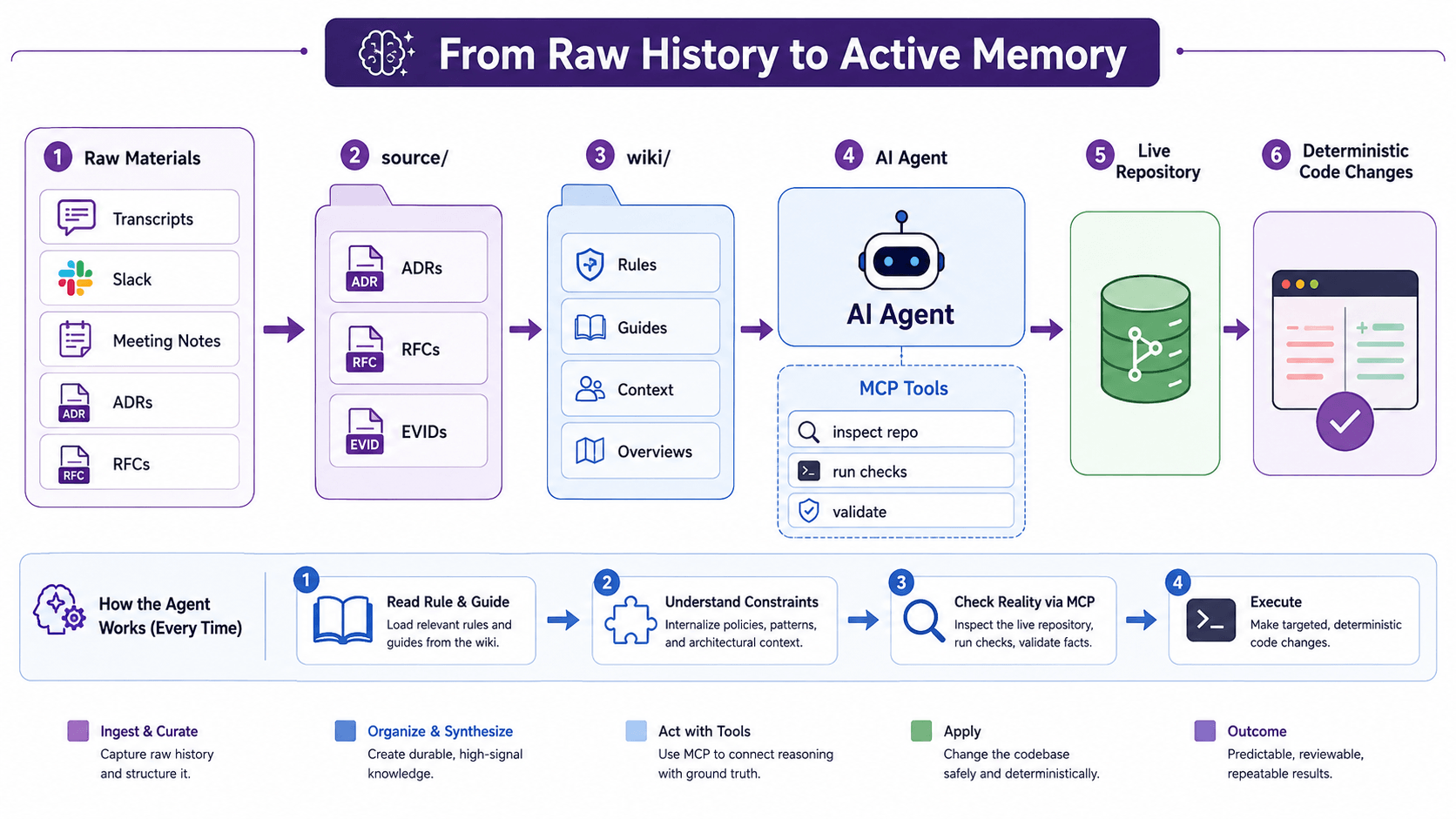
We fixed this by introducing a strictly layered documentation workspace: source/wiki/
This is different from just throwing a steering file at the AI. Steering files hold formal constraints like context, rules, and skills. They function as passive markdown loaded into the context window. They sit alongside ADRs and meeting notes as a source of truth for how things should be done, but they remain optimized for recording decisions rather than active execution.
The wiki/
The agent shouldn't have to read dozens of ADRs and a steering file to guess the right path. The wiki translates raw ADRs + RFCs + EVIDs into actionable Rules + Guides + Context + Overviews.
The wiki becomes the active memory layer. MCP (Model Context Protocol) tools become the capability layer the agent uses to check what is true in the live repository right now.
Structuring the wiki schema around intent removes ambiguity. When an AI agent reads a page, the intent category explicitly maps to an agent behavior: enforce, execute, understand, or orient.
Let’s look at some Server-Side Rendering (SSR) examples of an intent-built wiki (if you have ever spent a weekend debugging a memory leak only to realize an AI tried to use window.localStorage
When the agent reads a wiki page with intent: rule, it treats the content as a hard constraint that it must never violate when writing or reviewing code.
Scenario: You ask the agent to add a scroll-position tracker to a shared component.
The Rule: The agent is already blocked from using window
Agent Behavior: The agent knows it must not write window.scrollY
When a page declares intent: guide, the agent uses it as the recommended workflow. It informs the agent's plan but doesn't replace its judgment or orchestrate the tools. It just provides the domain-specific procedure.
Scenario: You say, "Make this component SSR-safe."
The Guide: Outlines a specific workflow: detect violations, evaluate skip conditions, apply fixes in preference order, check for hydration issues, and verify.
Agent Behavior: The agent reads the guide to understand the workflow, then executes it using its own tools and skills. It scans first instead of guessing. It checks skip conditions so it doesn't over-fix. It applies platform-agnostic fixes before resorting to browser-scoping. The guide prevents the agent from taking lazy shortcuts like wrapping everything in afterNextRender
When a page declares intent: context, the agent uses it as background knowledge. It explains why things are the way they are, informing tradeoff discussions without constraining actions.
Scenario: The agent notices an inconsistency in the codebase regarding the SSR architecture, or you explicitly ask why we don't render on every request instead of using a cache.
The Context: The wiki explains the design drivers. Zero-degradation guarantees, decoupled rendering costs, instant rollbacks, and predictable load. It also notes the accepted tradeoff of cache staleness.
Agent Behavior: The agent reads the context to understand whether an inconsistency is intentional or just tech debt. It uses this knowledge to explain the design drivers to you, providing reasoning so you can make an informed decision about whether to deviate from the architecture.
Give the agent this second brain and massive monorepo maintenance actually becomes manageable. The agent stops rebuilding its architectural context from scratch every single time.
It first reads the Wiki Rule to understand its constraints, then reads the Guide to understand the workflow. Finally, it calls MCP tools only when it needs to inspect the current repository state or run validation scripts.
Dumping raw project history and sprawling steering files into an LLM’s context window is like hiring a brilliant engineer with severe amnesia. They guess. They hallucinate. Eventually, they break things because they lack the context of why the codebase exists in its current state.
An intent-driven wiki stops you from hoping the agent pieces together the right architectural puzzle. You are giving it a persistent, structured memory.
The return on investment is obvious:
Stop reviewing PRs where the AI invented a new library or bypassed your security layers just because it misread a three-year-old ADR.
Architectural debates are settled once, codified as a Rule or Guide, and enforced across every agent task.
Building a second brain for your AI accidentally creates a living onboarding manual for your human engineers.
You don't need to halt production to completely overhaul your documentation today. Start small. Take your team's most frequently violated engineering rules. Extract them into a wiki/
Intermediate workshop
Master the principles behind AI code generation and build a context ecosystem that works with any AI coding assistant.
Learn more
The dominant picture of Agentic UI is wrong. You imagine a Copilot-style chat panel grafted onto an existing product: a sidebar that takes natural language, calls a model, and prints a reply. You ship it, call it agentic, and move on.

Executing design system migrations in large codebases is often cumbersome and slow - component updates, testing coordination, and knowledge management consuming thousands of man-days.
