Legacy Code Is Contaminated Context

Table of Contents

You ask an agent for a small change. It returns code that compiles, fits the files around it, and passes a quick review. A week later, someone notices it uses the exact pattern the team has spent a year trying to retire.
The code was never broken. Broken code is the easy case: it fails a test or throws at runtime, and someone fixes it before lunch. The costly output is the change that looks right and brings a retired decision back into new work.
This is not a model-quality problem. The agent did what it was built to do: read the surrounding code and match it. The hard part is what "match the code" means when the code is years of decisions, good and bad, layered until you can't tell which layer is load-bearing.
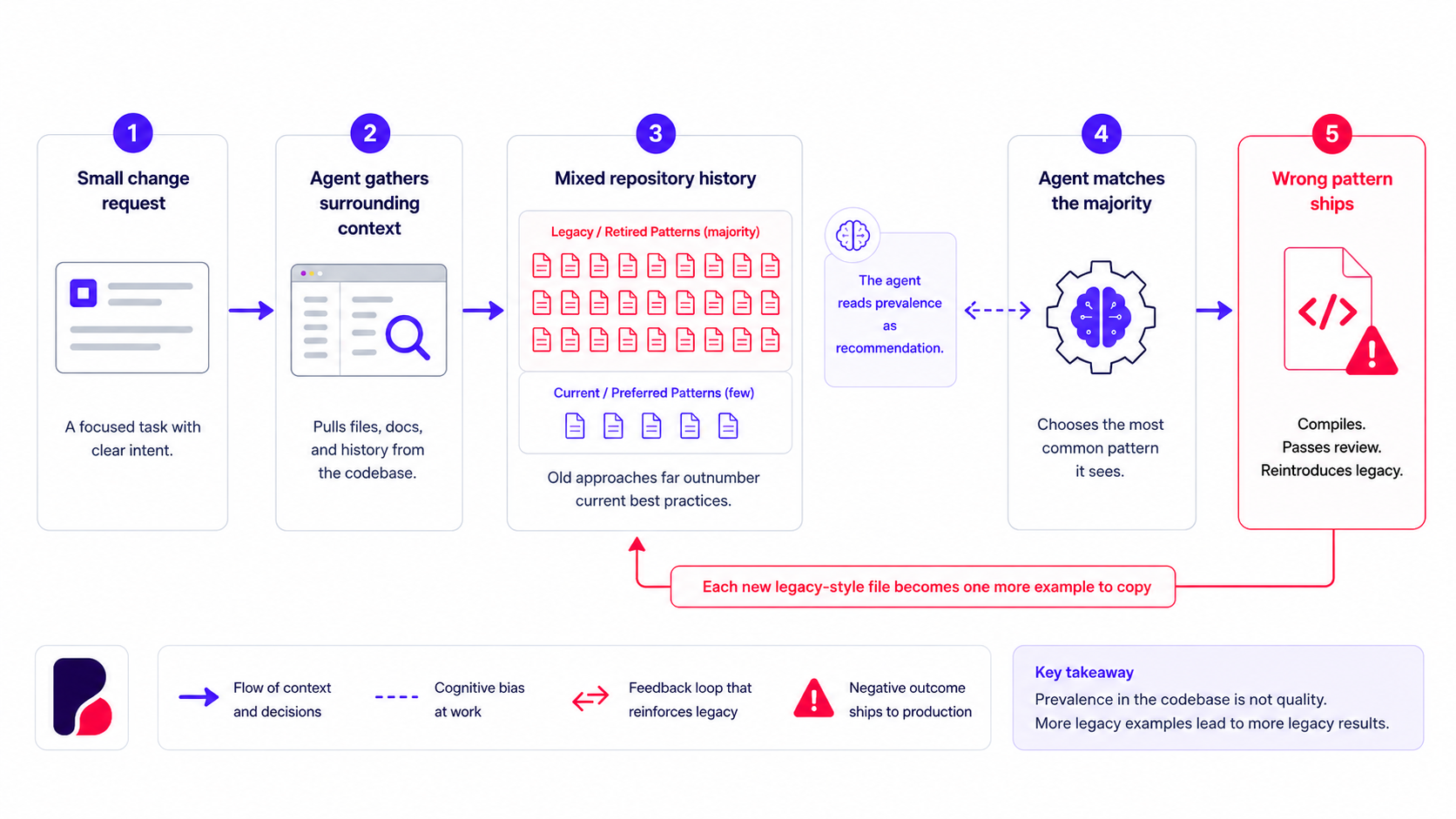
Your agent copies the most common pattern
The agent cannot tell either. It builds its context from what sits near the task and what looks similar. Nothing in the code marks which patterns the team still trusts. A clean, modern implementation and an old copy-pasted shortcut arrive with the same authority, and the agent treats them as equals. Where the careful pattern shows up in four files and the shortcut shows up in two hundred, the shortcut is more likely to land in the agent’s context and be read as the way things are done here.
A new engineer hits that same old code and asks whether this is how it should be done. The agent does not ask. It follows the majority until you ask the better question or set the standard yourself. Left alone, it reads prevalence as a recommendation.
The agent picked the most common option. In an old repository, that is often the worst one.
The codebase most AI advice doesn't describe
A lot of good advice exists on working with AI inside a clean project. Set your conventions, keep the structure tight, give the agent a clear path and let it follow. That advice is sound, and it rests on something a clean project has for free: roughly one way to do any given thing, and that one way is worth copying.
An old codebase does not offer one way. It offers twenty. Years of a product accumulate layers from everyone who passed through, each solving the same problem their own way, and most are still in the tree. The agent sees all twenty at once, with no way to tell which one is current and which one the team has been meaning to delete for years.
Prevalence wins, and it ships a security bug
Take a routine request: add a service that loads and caches a user's saved items.
The agent scans the project, finds dozens of services that cache the same way, and copies them:
// the shape dozens of services in this repo share
const cache: Record
That cache lives at module scope, so one object is shared by every request the process handles. In a browser, with one user per tab, it is harmless, so the repo is full of it. Under server-side rendering it is not: the process outlives the request, and the second user gets the first user's items.
A few newer services cache differently. They key the data by user and hold it on the service instance. Angular normally creates a fresh application and injector per SSR request, so instance state does not survive across users the way module-level state does, and the per-request cache lasts only as long as the request:
// the shape three newer services use
@Injectable({ providedIn: "root" })
export class SavedItemsService {
private http = inject(HttpClient);
private cache = new Map
Both patterns sit in the repo, the leaky one across dozens of files and the safe one in three. The agent is not being careless. Prevalence gives the old pattern more chances to land in its context, so it behaves as if it is counting, and the old pattern has the votes. It compiles, passes review, and goes out with a cross-user leak that a security audit catches three months later, leaving one more example for the next agent to copy.
And it compounds. A human team grew its legacy at the speed of typing; an AI-assisted team grows it at the speed of generation. Every new file in the old style is one more vote for the old style, and the cleanup you keep deferring gets bigger with every sprint.
The cheap wins help, but they are triage
There are sensible moves here, and most teams reach for them:
Keep the old code out of reach. The agent cannot imitate what it never reads. Scope what it is allowed to retrieve, and keep the oldest, worst directories out of its context so they never enter the window. An ignore file is the blunt version, and it still helps.
Write the standard down. A rules file hands the agent your current convention instead of leaving it to guess one from the majority. A few lines (the typed client, no module-level caches) are enough to move the default.
Give it something good to copy. Point the agent at two or three blessed, current implementations. Imitation is the whole problem, so aim it at the files you would be glad to see cloned.
Fail new code on the worst pattern. A lint rule on your single most damaging habit stops it at the gate. One caveat that matters: you cannot make it fail the whole build, because the legacy is full of the pattern and the build would stay red. Scope it to changed lines, so it guards new work without asking you to refactor years of history first.
Each helps; none is the fix. They all do the same defensive thing: keep the agent away from bad context. What none of them buys you is a reliable source of good context, one that stays true as the codebase and the team keep moving. Building that source is the harder, separate piece of work.
Your captured context drifts from reality
Say you do all of that. You have taken a snapshot of how the team works today, and the codebase will not hold still for it. Six months on, half is stale, and you are steering the agent with a map that no longer matches the ground. You have not removed bad guidance; you have replaced it with confident, stale guidance, which reads as authoritative and is worse.
Then there is the second copy of the problem. Each assistant reads its own kind of context file, in its own format. Most teams settle on one tool as the default and let engineers reach for others, so the same guidance lives in several files and drifts apart. You fix one and forget the rest.
Who owns the snapshot, and who notices when it drifts from the code, or from the other tools?
Govern the reasoning, not another rules file
Start with what is measured. Research on repository-level code generation shows that what an agent retrieves changes the code it writes: pulling in relevant code from across the repository, not just the current file, lifts completion accuracy by more than ten percent (RepoCoder, EMNLP 2023). That is the premise, not the answer. In a legacy repo, where the old patterns dominate, "use the repository" and "use the bad pattern" are the same instruction, so the job is to control what the agent sees, and a rules file is the weak version of it.
The durable answer cannot be another rules file, or "memory." It lives one level up: govern the reasoning, not the recall. The agent consults what the team has decided, each decision carrying a status, so it follows what is current and skips what has been superseded. The two look alike on paper. The table is where they diverge:

We run such a layer against a production Angular codebase, and the cache leak above is one entry in it. But a record rots as easily as a rules file if no one owns it. A validation date is only as good as whatever re-runs the detection query. Give the record an owner and run that query in CI, and drift trips a check instead of waiting for someone to notice. Get that right and the captured context stops drifting; skip it and you have a rules file with better intentions.
The catch: a small, clean project may not need this yet, and the cheap wins will hold. Legacy is where its absence shows first. A folder of records is the easy part. Keeping a layer of them honest as the code changes underneath you is the work, and that is its own subject, covered separately in our write-up on giving an agent a second brain.
Start with one record
None of this needs a big program. The cheap wins from earlier will improve the output this week. They cannot keep the agent honest as the codebase grows and the team turns over. So start with one record: take the decision that burned you, write it down with a status, a safe and an unsafe example, and a query that catches the unsafe one, and give it an owner. That is the first entry in the layer. Repeat it for the decisions that matter, and your legacy stops being the contaminated context the agent learns from.
Writing one record takes an afternoon. Generating records for a whole codebase, re-validating them as the code moves, and serving them to every agent in one format: that is the build, and it is what we do. It is worth a conversation when:
old code is dragging down what your AI agents ship, and the cheap wins have stopped holding the line;
you need an internal context layer for your agents and don't have one yet;
AI adoption is outrunning its guardrails, and cost, quality, or architecture drift are starting to show.
If that is the shape of your problem, the rest of the answer is a conversation, not another article.